Kontekst
Denne løsning blev bygget til edge-to-cloud IoT-systemer, hvor TLS, MQTT, gateways og ustabile netværk skaber drift over tid.
Målet var at flytte audits fra engangsvurderinger til et gentageligt kontrol-loop.
For den tekniske designkontekst, se blog-indlægget om problem og systemgrænser.
Intervention
Jeg designede og implementerede en evidens-first audit engine med deterministisk flow:
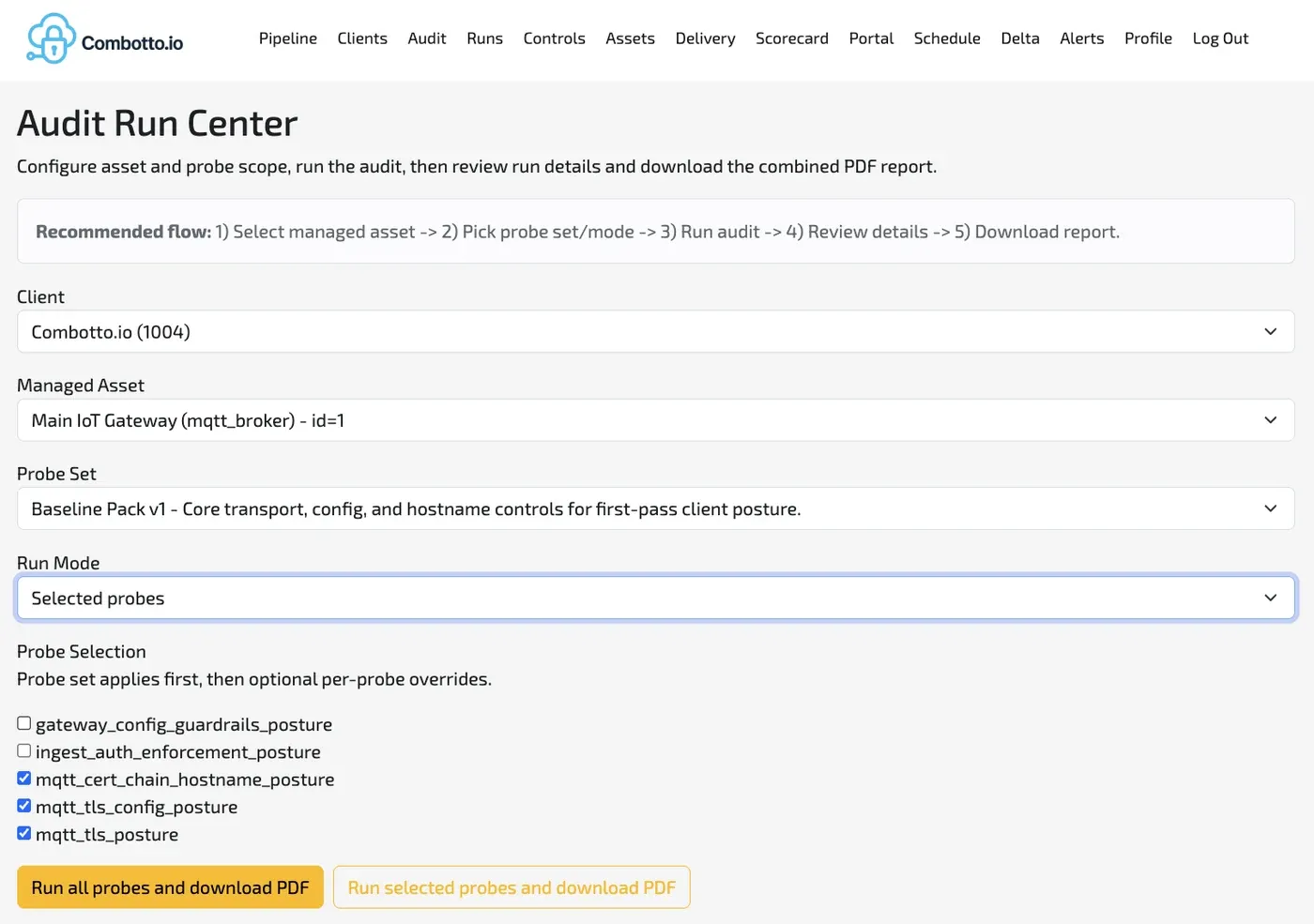
- Indsaml probe-evidens fra target assets.
- Normaliser og evaluer evidens med versionerede regler.
- Generer issue drafts og report artefakter.
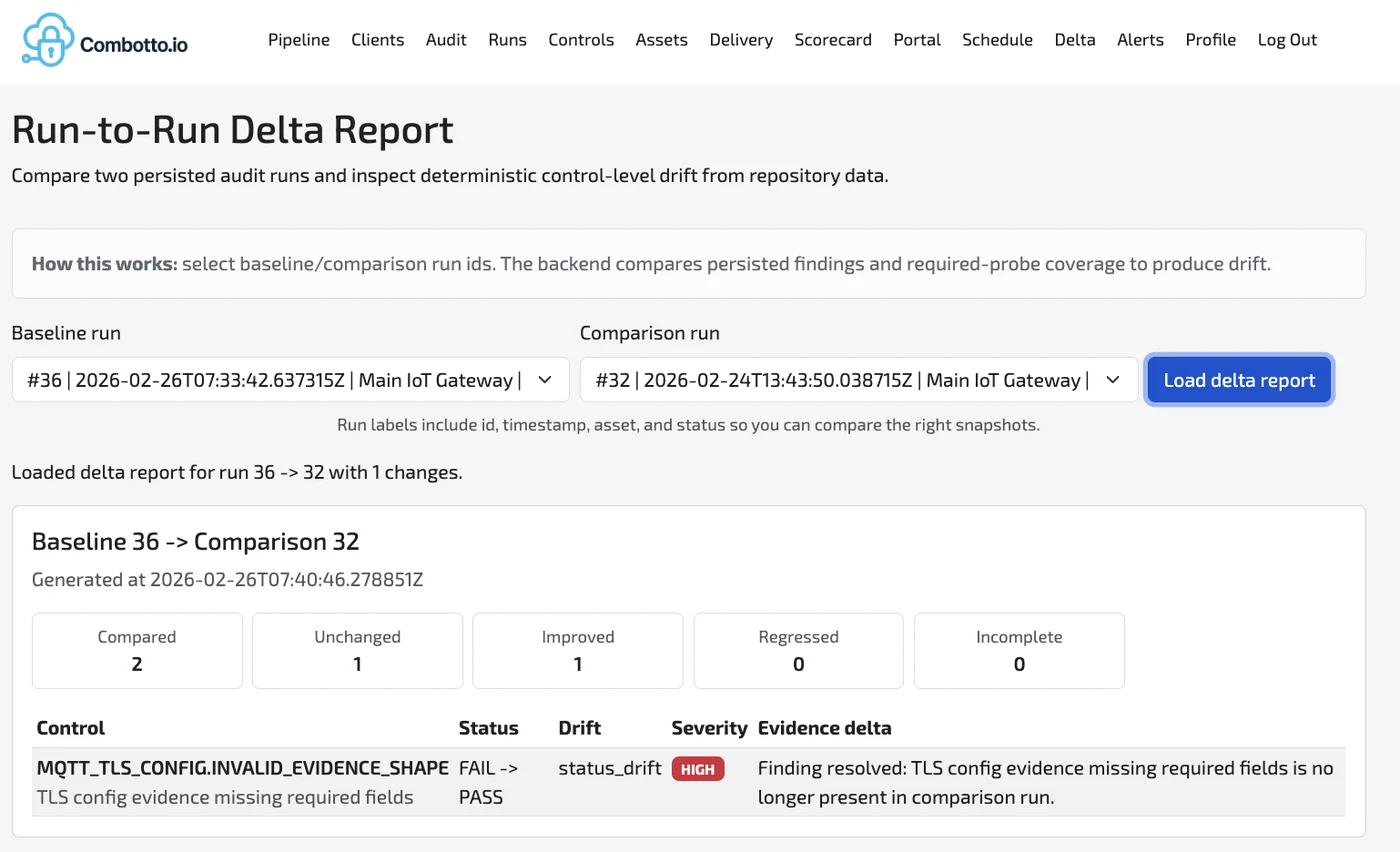
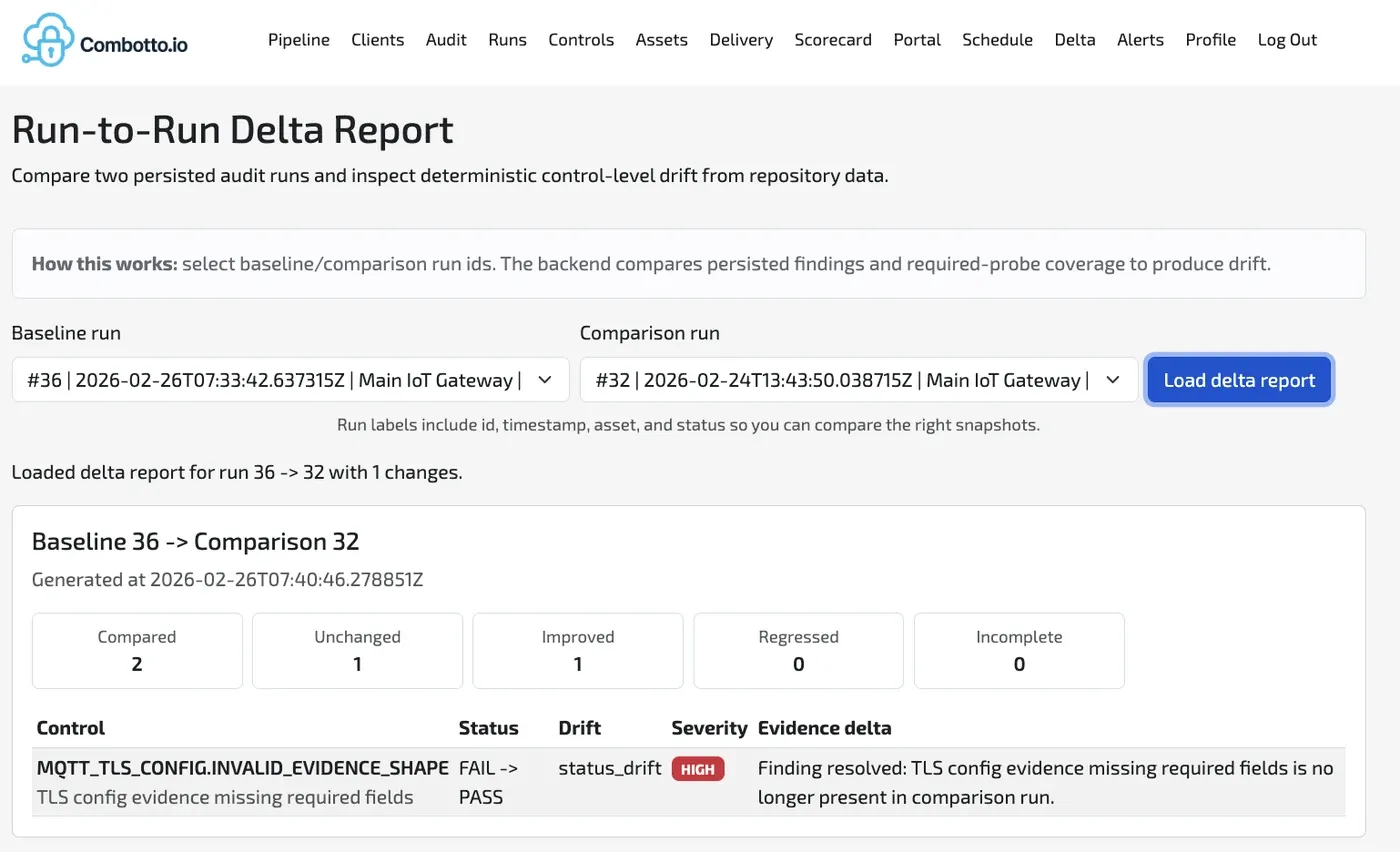
- Sammenlign runs for at synliggøre deltas og regressioner.
- Omsæt resultater til en genkørbar backlog.
Tekniske implementeringsdetaljer er dokumenteret i:
Evidens
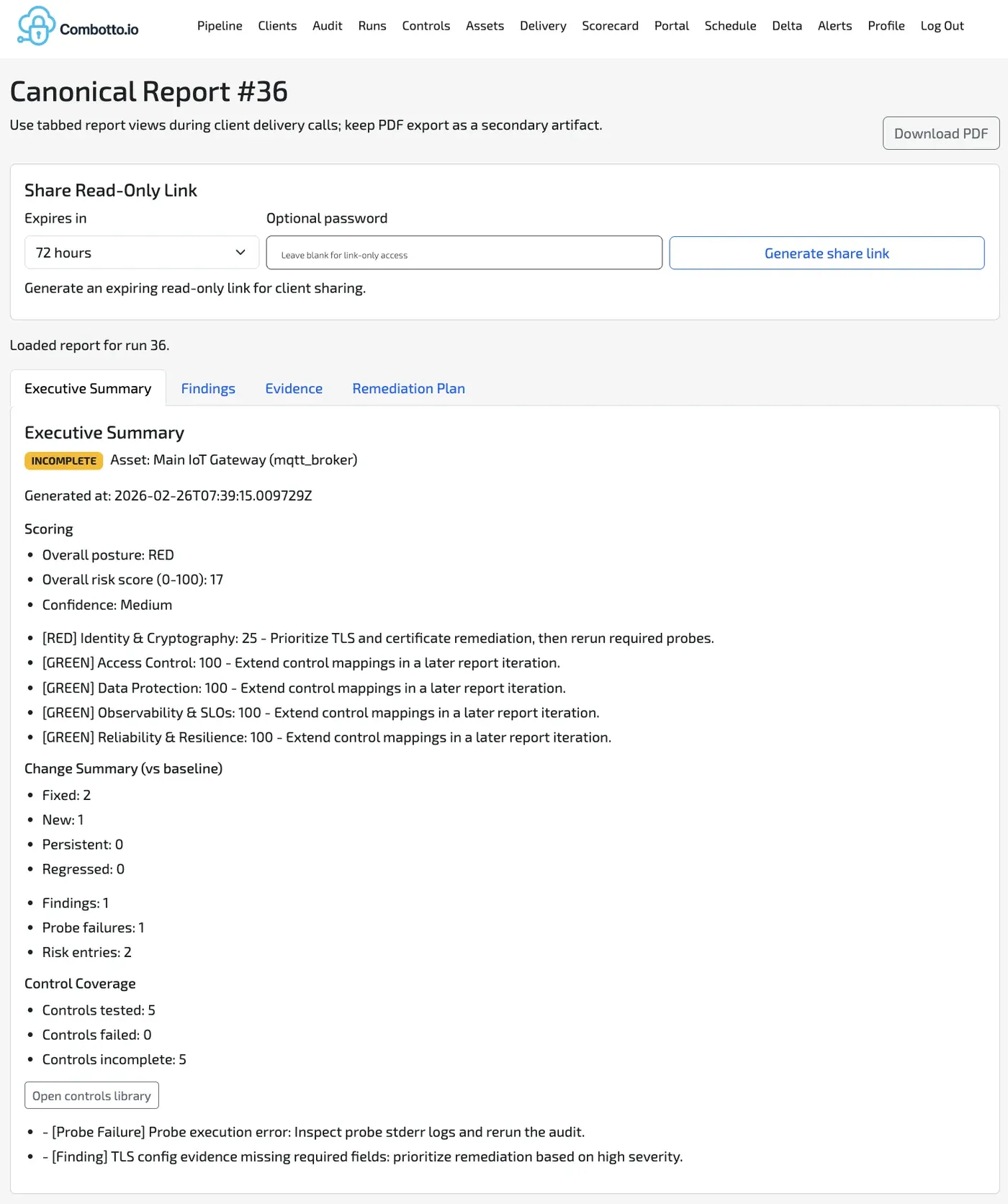
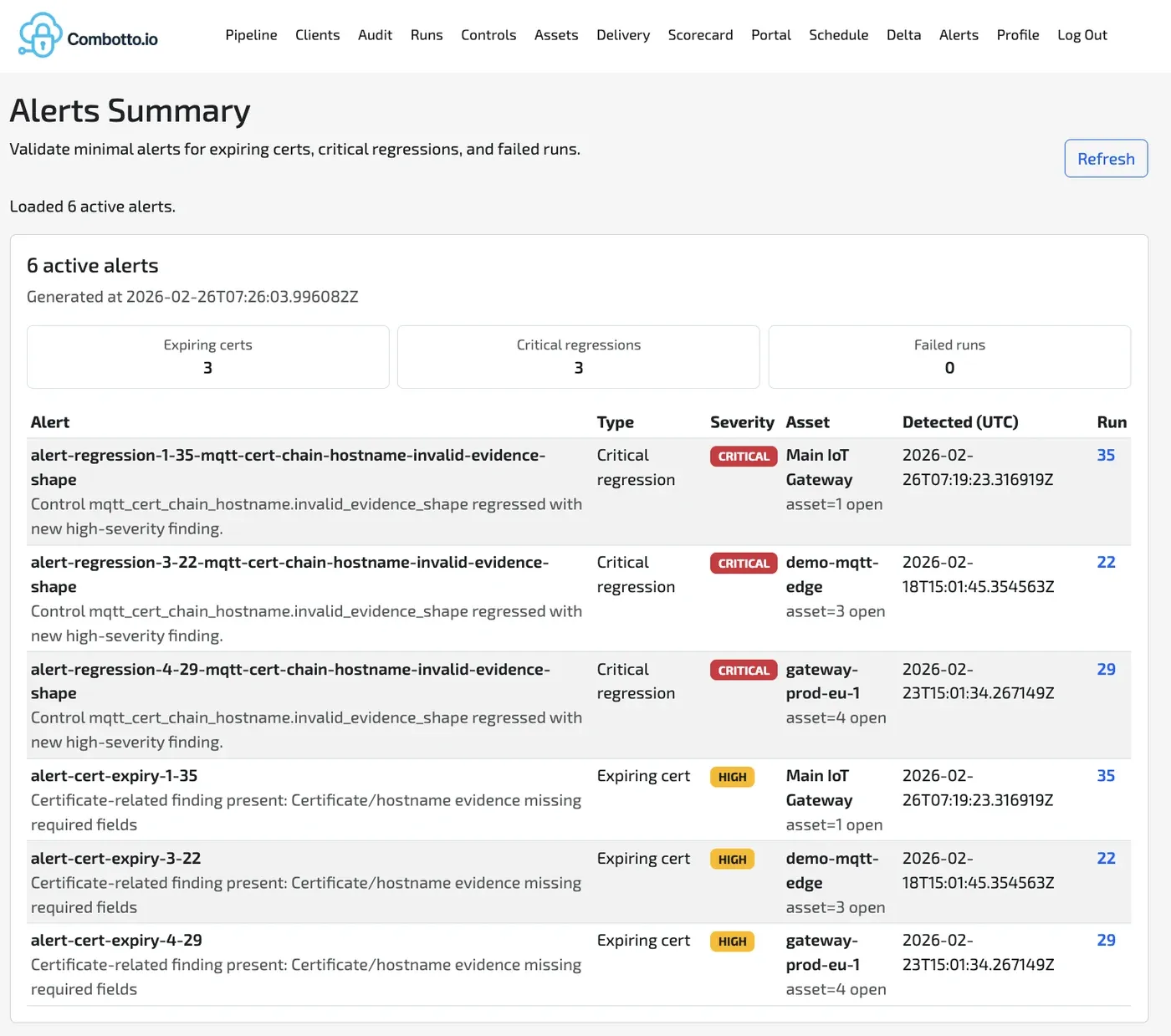
Platformen genererer auditerbare artefakter, ikke kun anbefalinger:
- Struktureret rå-evidens fra hver probe-eksekvering (JSON-kontrakt pr. check).
- Regel-evaluerede findings med severity og issue keys.
- Run records til run-to-run sammenligning og drift-detektion.
- Backlog-ready issue outputs, som kan planlægges og re-verificeres.
Det giver en “show, do not tell” audit-tilgang, hvor hver finding har sporbar evidens og en deterministisk rerun-sti.
Outcome
Resultater fra implementeringen:
- Audits gik fra manuelle snapshots til repeatable, evidensbaserede runs.
- Findings blev målbare mellem cyklusser via deltas og regressionschecks.
- Reliability, sikkerhed og observability kunne vurderes i samme operating model.
- Opfølgende arbejde blev operationelt gennem genererede, prioriterede backlog-items.
Næste skridt
Denne engine er et genanvendeligt referenceprojekt for, hvordan jeg arbejder med evidensmodellering, deterministisk audit-eksekvering og backlog-orienteret hardening i IoT-systemer:
- Læs deep dive’et for arkitektur- og implementeringsdetaljerne bag kørselsmodellen.
- Se resten af portfolioen for relateret arbejde med gateways, telemetri og driftssikkerhed.
Læs det fulde deep dive eller se mere portfolioarbejde.
Tech Notes
Små prober og deterministisk orchestration gør løsningen praktisk i rigtige projekter, hvor teams har brug for repeatability, sporbarhed og en kontinuerlig forbedringsvej.
Stack: Rust-prober + Scala/ZIO-service + Postgres + report/backlog generation + CI-venlig eksekvering.
